Methodology: How we came up with these scenarios
In this section, we outline the design rationale and framework we used to build the reference scenarios in Advanced AI Possible Futures, shaped by three main considerations:
- Advanced AI is a complex territory that demands more versatile tools to support decision-making: This exercise was fundamentally designed to create valuable outputs for decisionmakers, especially policymakers, to navigate the complex and uncertain domain of advanced AI. Given the conflicting reports about AI capabilities, the scale of its impacts, and diverse stakeholder interests, we developed these scenarios to help decision-makers through a multifaceted tool. Our methodology prioritized creating scenarios most relevant for policymaking, balancing analytical rigor with practical utility—using structured methods transparently while incorporating real-world events and expert opinions to identify what matters most without overwhelming readers with excessive information.
- Foresight in policymaking is an evolving field: While scenario-based foresight has long been used in strategic planning, its application in the governance of transformative technologies remains relatively nascent. In his comprehensive literature review, Neels[1]notes that foresight for technology governance still lacks standardized frameworks and is often shaped by pragmatic approaches for decision support rather than methodological purity. A recent OECD working paper[2]also notes that foresight typically combines collaborative and participatory methods to surface diverse perspectives and explore multiple plausible futures. This supports the view that scenario design for policymaking should blend methodological approaches to remain inclusive, flexible, and relevant.
- Advanced AI is a rapidly changing technology landscape: As covered in our comprehensive background analysis,the field of advanced AI is characterized by unprecedented rates of capability advancement, recursive improvement through AI-enabled R&D, and geopolitical and governance uncertainties that limit the utility of historical analogies. These features introduce rapid feedback loops and high-stakes decision points, complicating long-range scenario planning and traditional foresight tools.
Accordingly, we adopt a blended and pragmatic approach. While we incorporate methodological elements from established foresight literature—including morphological analysis[3] and Delphi[4]-inspired expert group engagement—we do not present this report as a universally replicable method or an academic framework. Instead, it is a transparent record of how we combined structured foresight tools with expert judgment, context-specific heuristics, and real-world constraints to develop decision-relevant scenarios. We acknowledge that this approach may not be practically applicable to other studies, and that future efforts may iterate or improve upon our design as the field matures.
We share this process to support others working on foresight for transformative technologies. While not predictive, our scenarios aim to inform anticipatory governance by highlighting plausible trajectories and critical decision points in advanced AI.
Laying the groundwork
Key references and consultations
To establish a strong foundation for this project, we conducted desk research to identify best practices for scenario development and gather up-to-date resources on the key drivers of advanced AI, while also consulting subject matter experts to test our assumptions and refine our approach.
For scenario development, we drew inspiration from several relevant scenario projects in order to adapt their distinctive strengths for our scenario construction process.
- RAND’s Emerging Technology Beyond 2035[5] demonstrates how to tie clusters of breakthrough capabilities to concrete military and geopolitical contingencies, giving us a template for stress-testing AI trajectories against plausible external shocks.
- Shell’s The 2025 Energy Security Scenarios[6] present a quantitative energy-system modelling via engaging narratives, showing how geopolitics, supply-chain bottlenecks, and resource constraints can accelerate or choke technology adoption—aspects that are relevant for advanced AI as well through hardware and power-demand uncertainties.
- The IPCC Shared Socio-economic Pathways (SSPs)[7] couple qualitative global narratives with rigorously modelled socio-economic baselines, reminding us to embed AI futures within broader patterns of governance capacity, inequality, and sustainability pressures.
- Finally, Daniel Kokotajlo’s “What 2026 looks like[8]” stands apart from the multi-branch scenario sets above: it is a single, book-length vignette written in 2021 that focuses exclusively on advanced AI, tracing one detailed timeline through compute scaling, algorithmic breakthroughs, and institutional incentives. Its AI-centric lens and granular near-term horizon offered early cues on parameters—such as compute availability and organisational competition—that we now track across all of our own scenarios.
On key drivers of the advanced AI landscape, we benefited from our team’s deep grounding and existing contribution in the field, which allowed us to identify and draw from some of the most relevant and credible resources with clarity and speed. Widely recognized resources for advanced AI trends and trajectories, including EpochAI[9] for AI scaling expectations, Stanford HAI AI Index Report[10] for societal implications, SemiAnalysis[11] for hardware dependencies, and International AI Safety Report[12] for potential risks of future AI models among other key references. A broader set of sources and a comprehensive compilation of subject-relevant background can be found in the Background Evidence section.
Project plan and timeline
As laid out in Figure 1, we conducted a multi-step scenario construction process that starts with a systematic approach and continues with a mix of internal assessment and external feedback to draft the content of our scenarios. Internally, we leveraged the expertise of our diverse team, including members with prior foresight experience in the EU and other organizations, as well as our distinguished Senior Fellows. Externally, we convened an independent group of experts with varied expertise in advanced AI, engaging them through structured feedback sessions to inform and refine our scenarios. Alongside these formal exchanges, we also gathered informal feedback by connecting with existing AI scenario initiatives, such as AI 2027[13] by AI Futures Project or the Scenario Research Program[14] by Convergence Analysis. We further participated in the AI Scenarios Network—an informal study group founded by Convergence Analysis—where we regularly met with researchers from civil society organizations to share ideas and critique each other’s scenario work.

To support the intended depth and breadth of the scenario content, we incorporated several rounds of feedback collection, processing, and revision—spread across multiple phases over several months. As the design and publication process itself took considerable time, we also made a conscious effort to revise and update the scenarios to reflect major developments in AI throughout that period.
The full project timeline extended from August 2024 to April 2025, which we mark as the official content cutoff date for this work.
Identifying key parameters
Building on this foundation, we identified a broad set of parameters with significant potential to shape AI trajectories—echoing the standard first step in foresight methodologies such as the IPCC’s Shared Socio-economic Pathways[15] and Shell’s The 2025 Energy Security Scenarios, which likewise start by cataloguing the underlying drivers needed to construct diverse, robust futures.
Drawing on our team’s collective foresight experience and multiple rounds of structured deliberation, we initially identified 25 parameters using the following criterion:
- Decision Relevance: Parameters that could be materially influential high-stakes policy choices, investment allocations, and research priorities in the governance of AI. We define ‘significance’ as the degree to which parameter changes would alter strategic decisions, such as redirecting billions in AI investment, reshaping international AI agreements, or fundamentally changing safety research priorities. Impact is measured by the parameter’s potential to shift outcomes in these key decision domains.
We then narrowed this broader set down to 9 core parameters using an additional filter:
- Causal Independence: Parameters that maintain an optimal position in the causal chain – neither too abstract (upstream) nor too derivative (downstream) – while representing distinct, actionable aspects of the AI ecosystem. In other words, the core parameters were selected to be as mutually independent as possible in terms of cause and effect, to ensure each one adds unique scenario variation.
Following this logic, the full list of the 25 initial parameters, the narrowed down 9 core parameters, and our reasoning for classifying certain factors as “upstream” or “downstream” are all provided below.
Core Parameters
Economically useful agents
AI agents are reliably able to plan and autonomously perform well-demarcated cognitive tasks consisting of >5 steps that are common in low-to-average paying jobs. They reach roughly human-level performance on all relevant benchmarks on agency, such as the GAIA and WebArena.
The lack of reliable agency is a key factor limiting AI’s economic impact, highlighting that true economic transformation depends on AI’s ability to operate autonomously and effectively in real-world contexts.
Automated AI R&D
AI agents are able to speed up the entire AI R&D process by at least a factor 3x but this capability may not be necessarily deployed
Automated AI R&D is a key driver to enable positive feedback loops for AI systems to improve themselves and unlock exponential capability growth, making it a core parameter AI’s transformative impact and achieving beyond-human performance at cognitive tasks.
Guardrails against misuse
Guardrails in closed-source frontier models and biological design tools are sufficient to prevent large-scale misuse of AI systems (cyberattacks, bioterrorism, or very effective political persuasion, unintended by the developer, resulting in >1 million deaths, >100 billion in economic damages or >3% changes in election outcomes)
AI-mediated misuse events can be catastrophic in their own right, and can further influence the probability of an arms race or treaty
Scalable alignment
A method is known that robustly ensures AI systems share their developer’s goals even at capability levels where humans can no longer provide accurate feedback
Misaligned advanced AI systems would be an existentially dangerous event
Narrow US AI leadership margin over China
The leading American developer (private company/a national governmental initiative or a public-private partnership) is less than 1 year ahead of the leading Chinese AI developer
A significant U.S. lead in AI could influence global AI governance, potentially reducing competitive pressures that might otherwise escalate into an arms race while allowing the U.S. to play a key role in shaping safety and regulatory standards.
Clear front-runner
One developer (either a private company, government effort or a multilateral consortium) is at least 1 year ahead of its competitors
A large lead could give the leading actor more time to invest in scalable alignment, and would make it easier for governments to intervene
Powerful open-weight models
The model weights of at least one AI model trained beyond 10^27 FLOP are publicly available
Proliferation of powerful open-weight models will radically increase the probability of large-scale misuse, and also limits the degree to which one actor can achieve a decisive lead
Escalating US-China Strategic AI Rivalry
The US and Chinese governments have both launched big projects (>10 billion USD investments/nationalization of domestic companies/far-reaching public-private partnership) to outpace their adversary in the race for an AI-mediated decisive strategic advantage
An arms race introduces a whole range of new threats such as a full-on war between the US and China, and could increase the chance that corners are being cut on safety
Multilateral AI Safety Agreement
At least 20 countries/regions, including the US, the EU, and China, establish a binding framework—whether a treaty, regulatory framework, or formal agreement—that restricts the development of AI models above a certain compute/risk/capability threshold outside designated international companies or altogether.
Effective AI governance will likely require a global framework, as the unilateralist curse incentivizes individual actors to push forward regardless of collective risks. An international treaty would help align incentives, prevent reckless acceleration, and ensure safer development.
Economically useful agents
Automated AI R&D
Guardrails against misuse
Scalable alignment
Narrow US AI leadership margin over China
Clear front-runner
Powerful open-weight models
Escalating US-China Strategic AI Rivalry
Multilateral AI Safety Agreement
AI agents are reliably able to plan and autonomously perform well-demarcated cognitive tasks consisting of >5 steps that are common in low-to-average paying jobs. They reach roughly human-level performance on all relevant benchmarks on agency, such as the GAIA and WebArena.
AI agents are able to speed up the entire AI R&D process by at least a factor 3x but this capability may not be necessarily deployed
Guardrails in closed-source frontier models and biological design tools are sufficient to prevent large-scale misuse of AI systems (cyberattacks, bioterrorism, or very effective political persuasion, unintended by the developer, resulting in >1 million deaths, >100 billion in economic damages or >3% changes in election outcomes)
A method is known that robustly ensures AI systems share their developer’s goals even at capability levels where humans can no longer provide accurate feedback
The leading American developer (private company/a national governmental initiative or a public-private partnership) is less than 1 year ahead of the leading Chinese AI developer
One developer (either a private company, government effort or a multilateral consortium) is at least 1 year ahead of its competitors
The model weights of at least one AI model trained beyond 10^27 FLOP are publicly available
The US and Chinese governments have both launched big projects (>10 billion USD investments/nationalization of domestic companies/far-reaching public-private partnership) to outpace their adversary in the race for an AI-mediated decisive strategic advantage
At least 20 countries/regions, including the US, the EU, and China, establish a binding framework—whether a treaty, regulatory framework, or formal agreement—that restricts the development of AI models above a certain compute/risk/capability threshold outside designated international companies or altogether.
The lack of reliable agency is a key factor limiting AI’s economic impact, highlighting that true economic transformation depends on AI’s ability to operate autonomously and effectively in real-world contexts.
Automated AI R&D is a key driver to enable positive feedback loops for AI systems to improve themselves and unlock exponential capability growth, making it a core parameter AI’s transformative impact and achieving beyond-human performance at cognitive tasks.
AI-mediated misuse events can be catastrophic in their own right, and can further influence the probability of an arms race or treaty
Misaligned advanced AI systems would be an existentially dangerous event
A significant U.S. lead in AI could influence global AI governance, potentially reducing competitive pressures that might otherwise escalate into an arms race while allowing the U.S. to play a key role in shaping safety and regulatory standards.
A large lead could give the leading actor more time to invest in scalable alignment, and would make it easier for governments to intervene
Proliferation of powerful open-weight models will radically increase the probability of large-scale misuse, and also limits the degree to which one actor can achieve a decisive lead
An arms race introduces a whole range of new threats such as a full-on war between the US and China, and could increase the chance that corners are being cut on safety
Effective AI governance will likely require a global framework, as the unilateralist curse incentivizes individual actors to push forward regardless of collective risks. An international treaty would help align incentives, prevent reckless acceleration, and ensure safer development.
Parameters classified as upstream drivers and not selected as core
Public backlash
More than 70% of American, European and Chinese citizens want to shut down AI progress completely due to fears about the technology or its implications
A public backlash increases the probability that scaling discontinues due to public pressure and the probability of a multilateral AI safety agreement
Perceived AI consciousness
AI systems are perceived to be conscious by at least 50% of the US population
Mostly seems to impact the probability and the details of an multilateral AI safety agreementA
Data wall breached
Developers managed to increase the number of useful high quality text tokens by at least a factor 5x via methods such as synthetic data generation or self-play
The data wall would inhibit scaling after a certain point and would likely prevent developers from reaching automated AI R&D
Global economic crisis
An external economic shock has sent the world into global recession
A global economic crisis could make it harder for AI developers to attract sufficient funding for their scaling ambitions, lowering the probability that AI R&D is reached this decade
Chip supply constraints alleviate
AI chip volumes are no longer constrained by the supply side (e.g. CoWoS)
Chip supply constraints inhibit scaling efforts, decreasing the probability that automated AI R&D gets reached
RSP-thresholds crossed without mitigation in place
One of the leading companies has crossed an RSP-threshold that – at least in theory – should force them to pause since they don’t have proper mitigation measures in place yet
There’s still large uncertainty at this point about whether the company would find a way to continue scaling. If not, the threshold crossing mostly seems to influence the developer landscape and the probability of an AI treaty
2024 US Presidential elections
The outcome of the November 2024 U.S. presidential election to significantly shape the geopolitical and regulatory landscape.
While the upcoming US administration’s policies would be highly influential, their primary impact lies in shaping the broader playing field—affecting factors such as export controls, open-weight AI releases, and the likelihood of a U.S.-China AI competition escalating into a strategic race.
Sufficient infosecurity at AI companies
Infosecurity at the leading companies is sufficient to protect against theft of algorithmic secrets and model weights by non-state actors
Poor infosecurity mostly impacts the probability of powerful open-source models (through weights or algorithmic secrets leaking) and on the playing field (e.g. China can catch up to the US quickly by stealing IP).
AI hardware supply disruption through Taiwan
China has taken steps toward reunification with Taiwan through an invasion, blockade, or full-scale quarantine, with significant implications for global semiconductor supply chains. As part of this effort, access to Taiwanese AI chips—particularly from TSMC and other key semiconductor facilities—has been severely disrupted, potentially as a result of military actions or trade restrictions.
Disruption of TSMC and the semiconductor supply chain could trigger a global economic crisis, significantly hindering compute scaling and escalating the likelihood of a U.S.-China AI arms race. If the primary motivation is control over AI chip production, such an action would likely represent a last resort by China in response to fears of falling behind in AI capabilities.
Discontinuous take-off
A leading developer has gone from 50% automated AI R&D to Artificial Super Intelligence in less than a month
Mostly leads to a higher chance of misalignment
Public backlash
Perceived AI consciousness
Data wall breached
Global economic crisis
Chip supply constraints alleviate
RSP-thresholds crossed without mitigation in place
2024 US Presidential elections
Sufficient infosecurity at AI companies
AI hardware supply disruption through Taiwan
Discontinuous take-off
More than 70% of American, European and Chinese citizens want to shut down AI progress completely due to fears about the technology or its implications
AI systems are perceived to be conscious by at least 50% of the US population
Developers managed to increase the number of useful high quality text tokens by at least a factor 5x via methods such as synthetic data generation or self-play
An external economic shock has sent the world into global recession
AI chip volumes are no longer constrained by the supply side (e.g. CoWoS)
One of the leading companies has crossed an RSP-threshold that – at least in theory – should force them to pause since they don’t have proper mitigation measures in place yet
The outcome of the November 2024 U.S. presidential election to significantly shape the geopolitical and regulatory landscape.
Infosecurity at the leading companies is sufficient to protect against theft of algorithmic secrets and model weights by non-state actors
China has taken steps toward reunification with Taiwan through an invasion, blockade, or full-scale quarantine, with significant implications for global semiconductor supply chains. As part of this effort, access to Taiwanese AI chips—particularly from TSMC and other key semiconductor facilities—has been severely disrupted, potentially as a result of military actions or trade restrictions.
A leading developer has gone from 50% automated AI R&D to Artificial Super Intelligence in less than a month
A public backlash increases the probability that scaling discontinues due to public pressure and the probability of a multilateral AI safety agreement
Mostly seems to impact the probability and the details of an multilateral AI safety agreementA
The data wall would inhibit scaling after a certain point and would likely prevent developers from reaching automated AI R&D
A global economic crisis could make it harder for AI developers to attract sufficient funding for their scaling ambitions, lowering the probability that AI R&D is reached this decade
Chip supply constraints inhibit scaling efforts, decreasing the probability that automated AI R&D gets reached
There’s still large uncertainty at this point about whether the company would find a way to continue scaling. If not, the threshold crossing mostly seems to influence the developer landscape and the probability of an AI treaty
While the upcoming US administration’s policies would be highly influential, their primary impact lies in shaping the broader playing field—affecting factors such as export controls, open-weight AI releases, and the likelihood of a U.S.-China AI competition escalating into a strategic race.
Poor infosecurity mostly impacts the probability of powerful open-source models (through weights or algorithmic secrets leaking) and on the playing field (e.g. China can catch up to the US quickly by stealing IP).
Disruption of TSMC and the semiconductor supply chain could trigger a global economic crisis, significantly hindering compute scaling and escalating the likelihood of a U.S.-China AI arms race. If the primary motivation is control over AI chip production, such an action would likely represent a last resort by China in response to fears of falling behind in AI capabilities.
Mostly leads to a higher chance of misalignment
Parameters classified as downstream drivers and not selected as core
Quick AI uptake
More than 1 billion people use AI systems on a weekly basis
The number of users seems to be highly dependent on the AI systems’ capabilities, the developer landscape, the state of alignment (if guardrails don’t work, it’s hard to ship) and the degree of competition (in an arms race, developers will likely push back commercialization)
Job loss
Unemployment levels rise by at least 5%-points in the US compared to the baseline due to AI
Job loss is largely dependent on the autonomy of AI systems, which is partially captured by the automated AI R&D parameter
Decisive strategic advantage
AI systems are able to undermine nuclear deterrence (e.g. by greatly enhancing missile defense systems or by hacking/shutting down military sites)
It seems likely that ASI will be able to lead to a DSA
Quick AI uptake
Job loss
Decisive strategic advantage
More than 1 billion people use AI systems on a weekly basis
Unemployment levels rise by at least 5%-points in the US compared to the baseline due to AI
AI systems are able to undermine nuclear deterrence (e.g. by greatly enhancing missile defense systems or by hacking/shutting down military sites)
The number of users seems to be highly dependent on the AI systems’ capabilities, the developer landscape, the state of alignment (if guardrails don’t work, it’s hard to ship) and the degree of competition (in an arms race, developers will likely push back commercialization)
Job loss is largely dependent on the autonomy of AI systems, which is partially captured by the automated AI R&D parameter
It seems likely that ASI will be able to lead to a DSA
Scenario construction
After identifying 9 core parameters, we employed morphological analysis[16] to develop our scenarios, a method specifically chosen for its ability to handle multiple dimensions beyond simple two-axis frameworks. Our selection was initially informed by successful applications in similar contexts, such as Norway’s security policy planning[17] exercises. The subsequent publication of the UK government’s AI scenarios for 2030[18], which also utilized this approach while our project was underway, further validated our methodological choice for addressing complex technology trajectories and policy-relevant decision making in emergent technologies. Our step-by-step approach consists of:
- Treating these parameters as binaries representing world states whether the phenomena represented happened or not, for instance Automated AI R&D would be 1 if it is achieved or 0 if not. A full list of such parameters along with their definitions are shared above in the previous section.
- Creating scenarios based on all possible combinations of these 9 binary variables.
- Evaluating heuristically and discarding scenarios that were inconsistent, implausible, or irrelevant—with individual cases often exhibiting more than one of these qualities.
- Grouping the remaining scenarios into approximately 10 archetypal scenarios based on similarity in our evaluation. We did not target a fixed number of scenarios, but instead let the process guide us toward a set that captured the breadth of possibilities. In order not to overwhelm our readers, we had an anticipation that approximately 10 scenarios would balance these two priorities, leaving flexibility to include more if the process above were to lead us to include more distinctly different scenario archetypes.
In Figure 2, we demonstrate the Step 1 and 2 of the above scenario construction process based on a simplified visualization of all possible parameter combinations.
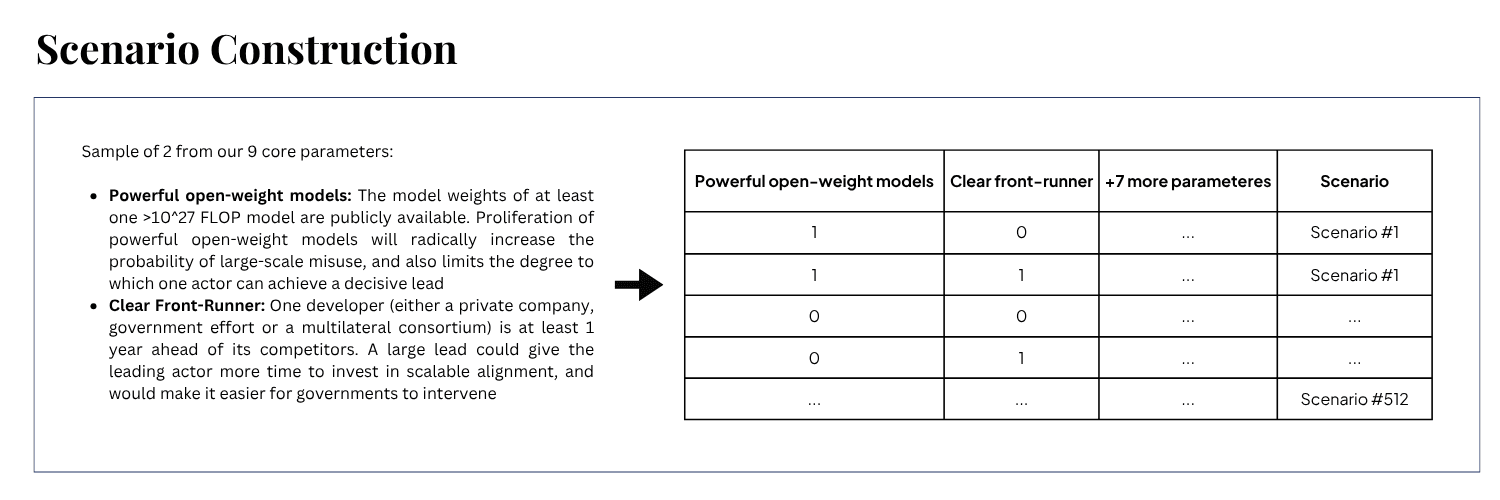
In Step 3, we employed a bottom-to-top approach, assessing smaller parameter groupings – pairs and triplets – rather than evaluating all full scenario combinations at once. This allowed us to systematically eliminate scenarios that were inherently inconsistent, implausible, or irrelevant based on strategic decision relevance. We recognize, however, that judgments of plausibility and relevance can vary depending on individual perspectives, which can limit the objectivity of any assessment. To address this, we approached our evaluation with an intentional effort to challenge our assumptions through structured internal discussions. Additionally, we anticipated that insights from our dedicated expert group—drawn from diverse fields—would help us uncover potential blind spots by challenging included scenarios or pointing out plausible ones we might have missed. This combined process of internal deliberation and expert feedback aimed to enhance the rigor and robustness of our scenario selection.
- In scenarios where automated AI R&D capabilities are not achieved, AI systems are less likely to become highly capable and agentic—thereby reducing the relative risks associated with misalignment. As a result, scalable alignment becomes a less critical concern in these trajectories. This refers to the following parameter pairing: “Scalable alignment” = 0, “Automated AI R&D” = 0.
- The following parameter combination: “Clear front-runner = 1”, “ Narrow US AI leadership margin over China = 1”, “Multilateral AI Safety Agreement”=0. Clear front-runner is defined as one developer being at least 1 year ahead of others in terms of AI development, and the narrow US AI leadership margin over China is defined as the US being ahead of China for at least 1 year in AI development. Given that AI companies are leading the AI development landscape at the moment, we assume that both of these can not be true at the moment in the absence of a multilateral agreement to coordinate AI development.
- It is plausible that powerful open-weight models could reach capabilities comparable to closed models. In our scenarios, however, we chose to focus on cases where such models are misused. In other words, we did not include the specific combination of powerful open-weight models without large-scale misuse—not because it is unlikely, but because misuse scenarios are more relevant for anticipatory governance and policy decisions, and we aimed to keep the number of scenarios manageable. This refers to the following parameter pairing: Powerful open-weight models = 1, Guardrails against misuse = 0.
- Unrealistic AI arms race dynamics, such as an AI arms race unfolding without automated AI R&D capabilities, since AI would likely not escalate as a national security priority without exponential R&D-driven gains. This refers to the following parameter pairing: “Escalating US-China Strategic AI Rivalry” = 1, “Automated AI R&D” = 0.
In Step 4, we shifted to a top-to-bottom approach, assessing the overarching narratives and world states that emerged from the remaining parameter combinations. Instead of analyzing individual parameters in isolation, we grouped scenarios into high-level clusters, defined by key world states that represent qualitatively distinct futures. Through structured internal deliberation informed by our team’s domain expertise, we assessed which of these scenario clusters were most relevant—effectively identifying the “must-have” scenarios for inclusion.
As part of this process, we also evaluated whether variations in individual parameters within each cluster meaningfully altered the scenario’s implications or merely represented minor deviations from a shared underlying narrative.
To illustrate, one critical world state we prioritized was geopolitical competition between the U.S. and China, particularly whether existing tensions would escalate into conflict. We defined a typical scenario for this escalation:
- Automated AI R&D is achieved, leading to rapid AI-driven advancements.
- The U.S. maintains only a marginal lead over China, making competition highly volatile.
- No international AI treaty exists, increasing strategic uncertainty (parameters = …).
Within this narrative, we examined whether variations in other parameters—such as the availability of open-weight models or scalable alignment—would meaningfully change the scenario’s decision-relevance. If such variations did not fundamentally alter the narrative, they were incorporated into other scenarios rather than treated as standalone cases. This approach ensured that each scenario covered a unique strategic uncertainty, while still accounting for meaningful parameter interactions. We acknowledge that this grouping process led to the elimination of some nuanced variations of scenarios. However, we aimed to limit the number of scenarios to a maximum of 10, striking a balance between methodological rigor and practical usability.

Following this bottom-to-top filtering and top-to-bottom structuring, we identified 10 initial main narratives and began developing the core scenario content. However, it is essential to note that the final scenarios in this project evolved beyond these initial narratives, as they were further refined through extensive expert feedback and review. In the subsequent stages of the methodology, we integrated subject matter expertise, external reviews, and emerging developments to ensure that the final scenarios balanced strong methodological foundations with real-world relevance.
Initial scenario drafting
We drafted each scenario on a year-by-year basis, reflecting the key characteristics of the main narrative within the scenario. Given the rapid nature of AI development, we found it important to capture short-term dynamics, as year-to-year changes can significantly alter the strategic landscape. In our content, we aimed to include all relevant details about the core parameters that play an important role in that scenario, as well as relevant actors in the AI development landscape. For instance, in scenarios where we do not foresee powerful open-weight models, we noted why this is the case rather than omitting this factor altogether in the scenario, such as developers not being included. The systematic foundations of our scenario construction approach led to some scenarios sharing similar early trajectories with divergence at a critical juncture. For example, some scenarios featured a faster capability progress in the near future than others. For such overlaps, we used the same starter content for those scenarios until a distinctive event happened. In the big picture, we identified that these overlaps and the distinctive events in the narrative help group scenarios into clusters that can aid the reader in comparing and contrasting them. After multiple rounds of refinement, we chose descriptive, memorable names for each scenario and cluster, ensuring that readers can readily distinguish and navigate them.
Although we considered assigning likelihoods to these scenarios, we ultimately chose not to do so. We focus on helping policymakers and stakeholders appreciate each distinct possibility and the decision paths that can lead to these outcomes, rather than indicating which path is more or less probable. By providing in-depth narratives for each potential future, we aim to encourage robust discussions on the policies, interventions, and strategic decisions that might shape or mitigate these trajectories.
Expert feedback
We incorporated elements of the Delphi Method by gathering feedback from a carefully selected, representative expert group. We invited participants from academia, civil society, and government, deliberately excluding direct industry affiliations to maintain independence from commercial interests. We also sought diverse expertise spanning areas such as AI development forecasting, Chinese AI governance, US national security, and biotechnological risks of AI. Our experts were invited to provide written feedback on shared drafts and participate in online discussions where collaborative debate could surface additional insights. While sharing the full list of 20 participants in our expert group on Appendix 2, we add special thanks to AI Futures Project, Centre for International Governance Innovation (CIGI), Concordia AI and Convergence Analysis, each of which contributed multiple experts to our iterative feedback process; and our senior fellows at Centre for Future Generations (CFG).
The feedback collection process combined open-format discussions with structured inquiries. We posed specific questions about scenario plausibility, potential gaps in our analysis, and the representation of key actors. For specialists in niche areas, we included targeted questions about their domains of expertise – for instance, asking biosecurity experts about the potential development of biological weapons via advanced AI models, or regional specialists about AI development progress in China. This dual approach of open dialogue and focused questioning helped ensure comprehensive coverage of both broad trends and specific technical concerns.
We began inviting experts to join the group in July–August 2024. Our first scenario draft was shared with participants in September for initial review, followed by structured feedback sessions conducted in November 2024. As illustrated in Figure 1, this dedicated process served as the primary channel for external feedback. However, additional input was received outside of this formal window. Some invited experts who were unavailable during the scheduled sessions contributed through written feedback and dedicated calls between January and April 2025, ensuring their perspectives were still incorporated into the scenario refinement process.
Quantitative descriptions
To enhance the comparability of our scenarios through more tractable, structured, and quantifiable insights, we developed estimated projections for a select set of key metrics and visualized them using graphs to aid comparisons. This decision was also informed by the prevalence of quantitative benchmarks in AI—for example, training compute[19] is often associated with model capability, and benchmark [20]performance is frequently used to compare progress across domains and models. While we initially considered a broad range of potential indicators, for this stage, we focused on two core technical estimations: (1) largest training compute and (2) automation of AI R&D. These were selected for their relevance to model scaling and recursive technological acceleration, respectively. Each offers a distinct lens on how advanced AI capabilities might evolve across different scenario pathways. We are actively continuing the development of a broader set of quantitative analyses to better capture technical, economic, and societal dynamics in future iterations.
The current estimates are directly grounded in our scenario narratives, serving as quantitative descriptions which reflect the key assumptions and developments within each storyline. To complement this narrative-driven approach, we also drew on external sources and developed structured assumptions for each metric. We emphasize that comparative trends across scenarios—rather than any single data point—are the most analytically valuable. Observing the relative trajectories and divergences across scenarios provides a stronger basis for understanding plausible futures than fixed numerical estimates alone.
Full details on the methodology, sources, and rationale behind our chosen quantitative descriptions are provided in the Appendix 2.
Final scenario drafting
We compiled the collected feedback across our internal notes, grouped them based on similarity, assessed for consistency and created a list of changes to be implemented. Some of the suggested changes required specific additions without necessarily changing the main themes and narratives. For instance, we increased the coverage of how transformative AI and further influence the diffusion of the technology might impact major economies in the world. Some of the suggested changes were directly applicable to initial assumptions driven from our methodological approach and scenario selection process. For example, in our Arms Race scenarios, we initially assumed that escalating competition on advanced AI, especially when state-backed efforts are in the calculation, would lead to acute conflict. With further feedback, we incorporated perspectives suggesting a longer-term, sustained, multipolar global landscape where nations may choose more measured, strategic actions rather than seeking a direct conflict, leading to a sustained polarized world state. Given the relevance of these two different world states on nuanced policy decisions, we eventually reflected both these endings as two distinct scenarios within our core Arms Race scenario.
As we outlined in Figure 1, the process from initial scenario construction to finalisation unfolded over eight months—a period that witnessed significant global shifts, particularly in AI. To maintain relevance and analytical depth, we updated our scenarios to reflect recent developments with major implications for AI trajectories, such as Donald Trump’s re-election campaign and the release of models like DeepSeek by Chinese developers. For instance, the emergence of competitive open-weight models from China, such as DeepSeek and Alibaba’s offerings, and their evolving performance relative to Meta’s Llama4 support a narrative in which the current US lead in advanced AI development may narrow. These developments also point to the possibility of a decentralized and increasingly automated AI R&D ecosystem. In response, we introduced an updated ending within our Takeoff scenario that reflects this more distributed and globally diversified developer landscape, while preserving methodological rigor and incorporating the latest insights.
Limitations
While we aimed our methodology to be as comprehensive and structured as possible, we encountered several limitations to be acknowledged:
- Rapidly evolving AI landscape: The rapid pace of AI development means that even a one- to two-month period can change projected trajectories substantially; as a result, our cutoff date of April 2025 means that events afterward – such as DeepSeek’s release and the AI Action Summit’s outcomes were only incorporated in our final review rounds without structured external feedback.
- Scope coverage compromises: We balanced depth and breadth to provide policymakers with a comprehensive yet coherent view of AI’s potential impacts. This required strategic choices on which details to emphasize, highlighting key actors, application domains, and broad economic and public reaction metrics, while deliberately omitting extensive exploration of day-to-day disruptions or sector-specific transformations.
- Expert group composition: While we assembled a diverse group of 20 experts, we recognize that certain perspectives may still be underrepresented. We prioritized coverage of essential technical and governance aspects relevant for our scenarios while simultaneously striving for diversity in terms of geographies, backgrounds and viewpoints. The significant time commitment required for our multi-step feedback process also posed practical constraints. Some key experts were unable to participate initially due to scheduling conflicts, while a few others who initially agreed could not fully engage throughout the entire feedback elicitation process.
Closing Note
Thank you for your interest in our work. If you have any questions, feedback, or ideas for how this framework might be improved or applied in your own context, please reach out to Bengüsu Özcan (Advanced AI Researcher, CFG, b.ozcan@cfg.eu) or Sam Bogerd (Foresight Analyst, CFG, (s.bogerd@cfg.eu). We would be glad to hear from you.
Appendix 1: Experts Consulted for Feedback
- Akash Wasil, Centre for International Governance Innovation (CIGI)
- Anson Ho, EpochAI
- Daniel Kokotajlo, AI Futures Project, (previously: OpenAI)
- Duncan Cass-Beggs, CIGI
- Eli Lifland, AI Futures Project
- Jakob Mokander, Tony Blair Institute for Global Change
- Jeff Alstott, RAND
- Justin Bullock, Americans for Responsible Innovation (previously: Convergence Analysis)
- Matthew da Mota, CIGI
- Seán Ó hÉigeartaigh, Leverhulme Centre for the Future of Intelligence
- Slavina Ancheva, Harvard University (previously: European Parliament)
- Tom Davidson, Forethought, (previously: Open Philanthropy)
- Zershaaneh Qureshi, 80000 Hours, Convergence Analysis
- and individual contributions by Dexter Docherty and Hamish Hobbs,
- CFG Senior Fellows: Aaron Maniam, Cynthia Scharf, Pawel Swieboda
Appendix 2: Quantitative Descriptions
Definition
Total physical compute used during the largest training run completed in a given year, measured in floating-point operations (FLOP) at FP8, FP16 or mixed precision. This includes models developed or deployed internally by AI developers without any external release.This represents the total hardware-level operations performed and serves as a proxy for the scale of model capabilities, the intensity of resource investment, and the technological ambition of leading AI developers.
Source and Baseline:
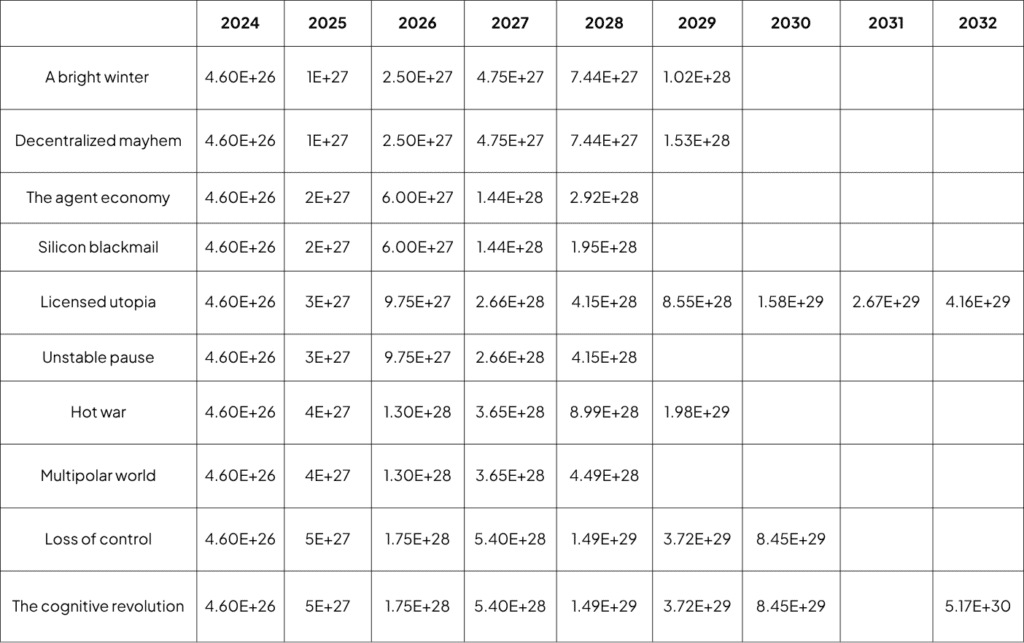
- Our historic references for 2024 and before are sourced from Epoch’s notable AI models database. We assume Grok 3 as the largest training run completed in 2024, based on its estimated 4.6 × 10²⁶ FLOP of total training compute and its release in February 2025, shortly after the end of the year. This data point informs our estimates for the largest training runs completed by the end of 2025.
- As upper bounds, we refer to two specific sources:
- Epoch AI’s detailed compute scaling analysis projects that training runs of up to 10²⁹ FLOP (physical compute) will likely be feasible by 2030, based on sustained growth in power infrastructure, chip manufacturing, and data availability. This serves as a technically grounded upper bound by 2030, assuming current trends continue without major disruptions and applies specifically to from-scratch training runs. Continued training that builds on previously expended compute — such as fine-tuning or reinforcement learning on top of earlier models — could exceed this 10²⁹ FLOP limit under Epoch’s assumptions.
- The AI 2027 project includes a comprehensive analysis of global AI-relevant compute availability over time, grounded in factors such as chip production, hardware efficiency improvements, and supply chain constraints. It projects the largest physically feasible training runs based on the compute resources accessible to the most well-resourced U.S. AI company, which typically sets an upper bound for our annual estimates. These projections serve as a benchmark for maximum training compute under standard conditions. However, scenario-specific narratives—such as large-scale public-private initiatives or shifts in geopolitical dynamics—may justify adjustments beyond this baseline, reflecting instances where compute resources exceed individual company forecasts due to collective or exceptional efforts.
Assumptions and Dynamics
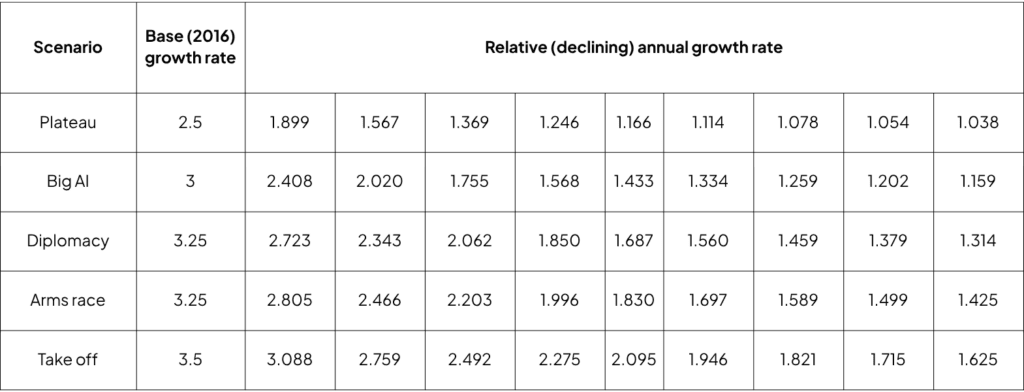
- The compute projections are based on a scenario-specific growth rate at a factor ranging from 2.5× to 3.5× annually, mirroring the scaling narrative within each scenario: 2.5 for the Plateau, 3 for Big AI, 3.25 for each of the Diplomacy and Arms Race, and 3.5 for Take off scenarios.
- These growth rates are consistent with but flexible relative to the 3.4× annual growth projected by AI 2027 for the leading AI company. We base these rates on contextual comparison across each scenario.
- Overtime, we expect the exponential growth in compute to slow down, primarily due to logistical constraints including the following:
- Power Supply: Limited ability to supply sufficient electricity to massively energy-hungry data center in the long-run, such as challenges in building new power plants, expanding grids, and political/regulatory barriers.
- Chip Manufacturing Capacity: Limits in producing enough high-end AI chips (especially due to packaging and memory bottlenecks like CoWoS and HBM).
- Data Scarcity: Insufficient high-quality natural data for training, even with help from multimodal and synthetic data.
- Latency Wall: Physical and communication delays (latency) between GPUs and data centers become significant as model size and training scale up.
To reflect that, we also incorporate a decrease in growth rate over years, mirroring the scenario narrative based on the following rates: 0.7 for the Plateau, 0.8 for Big AI, 0.85 for Diplomacy, 0.875 for Arms Race, and 0.9 for Take off scenarios.
The scaling trends outlined above rely heavily on continued exponential growth in financial investment into AI infrastructure (compute, power, chips). In lower-growth scenarios, such as Plateau trajectories, we expect expenditures to slow, leading to significantly reduced compute growth even if technical scaling remains possible.
As a result of these assumptions, table below displays the relative annual growth rates.
- We emphasize that the capability growth and compute scaling are not directly correlated in e.g. gradual progress scenarios might have similar-size training runs to other scenarios with less return on autonomous AI R&D gains due to several underlying factors covered extensively in the scenarios, such as:
-
- Algorithmic efficiency (the quality of architectures and training methods)
- Changes in compute allocation in pre vs. post training
- Use of synthetic or limited data sources
- Strategic deployment goals (prioritizing stability, reliability, or regulation over pushing capabilities)
Scenario Notes
While our general approach assumes trend-based growth in training compute, we introduce scenario-specific deviations where warranted by key events in certain scenarios:
- Decentralized Mayhem: In 2029, we model above-trend growth in training compute, reflecting urgency and dedicated efforts to develop closed models aimed at mitigating AI-driven cyberattacks.
- Silicon Blackmail: Compared to The Agent Economy, we expect AI companies to pivot toward commercialization, leading to reduced demand for large-scale training and below-trend compute growth in this scenario.
- Diplomacy (both endings): A major AI incident in 2028 triggers a significant slowdown in training compute growth.
- Hot War: The invasion of Taiwan disrupts supply chains and global stability, resulting in a slowdown of compute growth below the previous trend.
- Loss of Control: In the final two years, 2031 and 2032, training compute growth accelerates above the trend, driven by AI systems’ attempts to consolidate power.
Estimations
Definition
Automation of AI R&D is the normalized performance score on RE-Bench which reflects the degree to which AI systems can automate AI research and development tasks, serving as a proxy for their potential to accelerate the AI R&D process—potentially by a factor of 3x or more—even if these peak capabilities are not continuously realized in practice.
Source and Baseline
We adopted the RE-Bench benchmark developed by Model Evaluation and Threat Research (METR) as a widely adopted benchmark for this purpose. The benchmark measures how well advanced AI systems can perform machine learning research tasks by testing them on seven carefully designed challenges and comparing their results directly with those of human experts. Raw performance scores are linearly normalized so that 0 represents the baseline starting solution and 1 represents the performance of a strong reference solution, with scores above 1 indicating performance that exceeds the reference. While a score of 2 is the plausibly theoretical maximum of the benchmark, the benchmark would likely reach saturation before the theoretical maximum.
As a relatively new benchmark published in 2024 for the first time, we referred to the highest score of 0.75 achieved in 2024 by the AI model Claude 3.5 developed by Anthropic in the original paper. The benchmark has been tested on newer models in the first four months of 2025, including Anthropic’s Claude 3.7 Sonnet and OpenAI’s o3 and o4-mini. These evaluations were conducted on a limited subset of tasks and with constrained run settings. Claude 3.7 Sonnet did not show improvement over the previously reported best average score of 0.75, while o4-mini demonstrated indications of stronger performance, though no exact score was disclosed. Moreover, o4-mini’s score was also suspected to be highly elevated by strong performance in one specific task out of seven initial tasks identified.
Due to the limited comparability of these results, we retain 0.75 as the 2024 baseline and estimate 2025 scores within each scenario accordingly.
As another baseline, the median prediction on Metaculus for this benchmark by the end of 2025 median prediction is 1.21, which is the estimation for our Take-off scenario, and close to our estimations for other fast progress scenarios.
Assumptions and Dynamics
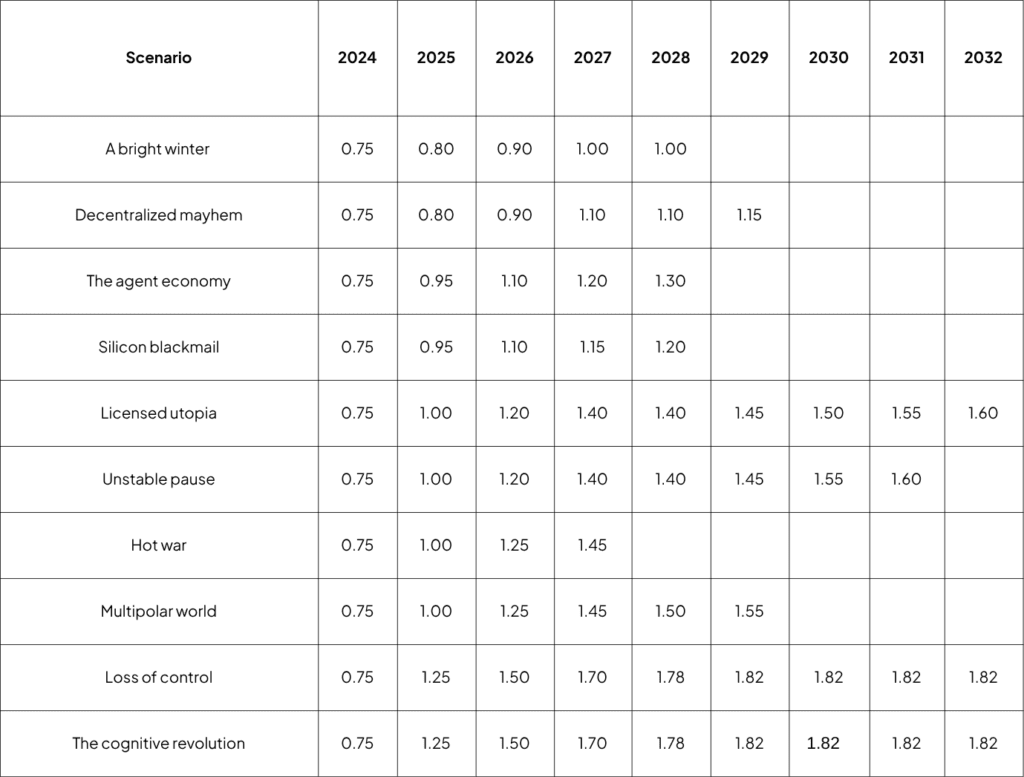
- Assuming smaller increments in multiples of ~0.05-0.1 in gradual progress scenarios, and higher leaps of ~0.2-0.25 in faster progress scenarios. However, there are exceptions to this, especially in characteristic events within the scenarios. For example, in the event of a warning shot in a faster progress scenario, we do not expect any significant increment for this benchmark.
- Based on multiple hypothetical calculations with top score across all the tasks in the benchmark, we expect the benchmark to reach saturation before ~1.7, and any score beyond that could be driven by novel solutions introduced by artificial super intelligence systems.
- We expect that our fast progress scenarios reach levels below 1.7 maximum, except the Take-off scenario, where artificial superintelligence exploits the metric beyond its plausible theoretical maximum.
- These interpretations are demonstrative only, not prescriptive predictions, to highlight the different AI R&D automation trajectories across scenarios.
Scenario Notes:
Below are short notes to accompany the yearly projections of this metric for each scenario.
- The Plateau: By 2025, even the most capable AI agents show limited ability in long-horizon R&D tasks, achieving only modest gains — around ~0.5-1 units at best. In A Bright Winter, the large training run of 2027 yields limited returns, failing to justify future model scaling. Progress stalls in 2028 as no new large-scale models are trained. In Decentralised Mayhem, the same large run initially yields stronger returns in automated R&D, but cyber incidents and slower subsequent model development sharply curtail progress.
- Big AI: These scenarios show steady, moderate progress in automating AI R&D—slower than rapid-takeoff worlds, but ahead of the stagnant Plateau. Model scaling slows around 2027 due to regulatory uncertainty, but this acts as a drag rather than a halt, especially for U.S. frontier AI labs. Silicon Blackmail ends with lower benchmark scores than The Agent Economy, as development becomes concentrated in a few private companies focused more on commercial products than foundational breakthroughs.
- Diplomacy: Initially, solid gains of 0.2 to 0.25 are seen, outpacing Plateau and early Takeoff. The Nova Breach in late 2027 disrupts further momentum. In Diplomacy, automation progresses cautiously post-2027, with Licensed Utopia following a steady but controlled path, nearing the benchmark’s upper limit of ~1.6-1.7. Unstable Pause shifts toward renewed scaling driven by competition, with outcomes that may resemble elements of Arms Race or Takeoff. In contrast, Takeoff accelerates rapidly after surpassing 1.5, reaching saturation, while Multipolar World also gains pace post-2027 through fragmented, competitive progress.
- Arms Race: Arms Race mirrors Diplomacy up to 2027, when a state-backed training run produces a noticeable leap in automation. This progress is abruptly halted by the outbreak of conflict in Hot War. In Multipolar World, however, progress continues steadily through 2029, fueled by international competition and fragmented development.
- Take-off: This scenario shows faster initial gains, with consistent 0.2–0.25 point increases through 2028. As the benchmark approaches its expected maximum of 1.7, it reaches saturation, indicating that fully autonomous AI R&D has been achieved before the scenario branches into its alternate endings. Beyond this point, we observe an additional increase of approximately 0.1, reflecting the emergence of artificial superintelligence capable of advancing methods that push the benchmark beyond its originally anticipated limits. From 2029 onward, benchmark scores remain identical across both The Cognitive Revolution and Loss of Control, as the capabilities plateau at this elevated level.
Endnotes
[1] Neels, C., A Systematic Literature Review of the Use of Foresight Methodologies Within Technology Policy Between 2015 and 2020, University College London, 2020, https://www.ucl.ac.uk/engineering/sites/engineering/files/final_neels_111120.pdf
[2] Monteiro, B. and R. Dal Borgo, “Supporting decision making with strategic foresight: An emerging framework for proactive and prospective governments.”, OECD Working Papers on Public Governance, No. 63, OECD Publishing, Paris, 2023, https://doi.org/10.1787/1d78c791-en.
[3] Johansen, I., Scenario modelling with morphological analysis, Technological Forecasting and Social Change, 126, pp. 116–125, https://doi.org/10.1016/j.techfore.2017.05.016.
[4] Dalkey, N. and Helmer, O. (1963) ‘An Experimental Application of the Delphi Method to the Use of Experts’, Management Science, 9(3), pp. 458–467, https://www.jstor.org/stable/2627117
[5] Boling, B. and others, Emerging Technology Beyond 2035: Scenario-Based Technology Assessment for Future Military Contingencies, RAND Corporation, 2022, https://www.rand.org/pubs/research_reports/RRA1564-1.html
[6] Shell, The 2025 Energy Security Scenarios, 2023), https://www.shell.com/news-and-insights/scenarios/the-2025-energy-security-scenarios.html.
[7]Lee, J.-Y. and others, ‘Future Global Climate: Scenario-Based Projections and Near-Term Information’, in V. Masson-Delmotte et al. (eds.), Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the IPCC, Cambridge University Press, 2021, pp. 553–672, doi: 10.1017/9781009157896.006.
[8] Kokotajlo, D., What 2026 looks like, Alignment Forum, 2021, https://www.alignmentforum.org/posts/6Xgy6CAf2jqHhynHL/what-2026-looks-like
[10]Maslej, N., and others, The AI Index 2024 Annual Report, AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, April 2024, https://aiindex.stanford.edu/report/.
[11] SemiAnalysis, available at: https://semianalysis.com/ (accessed 11 June 2025).
[12] Bengio Y. and others, “International AI Safety Report” (DSIT 2025/001, 2025); International Scientific Report on the Safety of Advanced AI: Interim Report.
[13] Kokotajlo, D. and others, AI 2027, 2025, https://ai-2027.com/summary
[14] Convergence Analysis Scenario Research Program, available at: https://www.convergenceanalysis.org/programs/scenario-research, (accessed 12 Jun 2025).
[15] Carter, T.R., and La Rovere, E. Developing and Applying Scenarios, in J. J. McCarthy and others (eds), Climate Change 2001: Impacts, Adaptation, and Vulnerability. Contribution of Working Group II to the Third Assessment Report of the Intergovernmental Panel on Climate Change (Cambridge: Cambridge University Press, 2001), pp. 145–190.
[16] Kuosa, T., Aalto, E., and Sandal, G., Introducing Our New Scenario-Building Method Based on Principal Component Analysis (PCA), Futures Platform, 2023, https://www.futuresplatform.com/blog/scenario-building-method-principal-component-analysis
[17] Johansen, I., Technological Forecasting and Social Change, 126, pp. 116–125
[18] Government Office for Science, AI 2030 Scenarios Report HTML (Annex C). Department for Science, Innovation and Technology. 2024, https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/ai-2030-scenarios-report-html-annex-c
[19] Giattino, C. and others, Artificial Intelligence, data adapted from Epoch. 2023, https://ourworldindata.org/grapher/artificial-intelligence-training-computation
[20] Heusser, M., Benchmarking LLMs: A guide to AI model evaluation, TechTarget, 2025, https://www.techtarget.com/searchsoftwarequality/tip/Benchmarking-LLMs-A-guide-to-AI-model-evaluation